There is an excellent Tim Minchin song called If You Open Your Mind Too Much, Your Brain Will Fall Out. I’m sad to report that the same is also true of your data and your science.
At this point in the story I’d like to introduce you to Emil Kirkegaard, a self-described “polymath” at the University of Aarhus who has neatly managed to tie every single way to be irresponsible and unethical in academic publishing into a single research project. This is going to be a bit long, so here’s a TL;DR: linguistics grad student with no identifiable background in sociology or social computing doxes 70,000 people so he can switch from publishing pseudoscientific racism to publishing pseudoscientific homophobia in the vanity journal that he runs.
Yeah, it’s just as bad as it sounds.
The Data
Yesterday morning I woke up to a Twitter friend pointing me to a release of OKCupid data, by Kirkegaard. Having now spent some time exploring the data, and reading both public statements on the work and the associated paper: this is without a doubt one of the most grossly unprofessional, unethical and reprehensible data releases I have ever seen.
There are two reasons for that. The first is very simple; Kirkegaard never asked anyone. He didn’t ask OKCupid, he didn’t ask the users covered by the dataset - he simply said ‘this is public so people should expect it’s going to be released’.
This is bunkum. A fundamental underpinning of ethical and principled research - which is not just an ideal but a requirement in many nations and in many fields - is informed consent. The people you are studying or using as a source should know that you are doing so and why you are doing so.
And the crucial element there is “informed”. They need to know precisely what is going on. It’s not enough to simply say ‘hey, I handed them a release buried in a pile of other paperwork and they signed it’: they need to be explicitly and clearly informed.
Studying OKCupid data doesn’t allow me to go through that process. Sure: the users “put it on the internet” where everything tends to end up public (even when it shouldn’t). Sure: the users did so on a site where the terms of service explicitly note they can’t protect your information from browsing. But the fact of the matter is that I work in this field and I don’t read the ToS, and most people have a deeply naive view of how ‘safe’ online data is and how easy it is to backtrace seemingly-meaningless information to a real life identity.
In fact, gathering of the data began in 2014, meaning that a body of the population covered had no doubt withdrawn their information from the site - and thus had a pretty legitimate reason to believe that information was gone - when Kirkegaard published. Not only is there not informed consent, there’s good reason to believe there’s an implicit refusal of consent.
{kind=link}
The actual data gathered is extensive. It covers gender identity, sexuality, race, geographic location; it covers BDSM interests, it covers drug usage and similar criminal activity, it covers religious beliefs and their intensity, social and political views. And it does this for seventy thousand different people. Hell, the only reason it doesn’t include profile photos, according to the paper, is that it’d take up too much hard-drive space.
Which nicely segues into the second reason this is a horrifying data dump: it is not anonymised in any way. There’s no aggregation, there’s no replacement-of-usernames-with-hashes, nothing: this is detailed demographic information in a context that we know can have dramatic repercussions for subjects.
This isn’t academic: it’s willful obtuseness from a place of privilege. Every day, marginalised groups are ostracised, excluded and persecuted. People made into the Other by their gender identity, sexuality, race, sexual interests, religion or politics. By individuals or by communities or even by nation states, vulnerable groups are just that: vulnerable.
This kind of data release pulls back the veil from those vulnerable people - it makes their outsider interests or traits clear and renders them easily identifiable to their friends and communities. It’s [happened before] (https://www.reddit.com/r/legaladvice/comments/3edf1s/im_a_gay_single_man_from_a_country_where_gaydeath/). This sort of release is nothing more than a playbook and checklist for stalkers, harassers, rapists.
It’s the doxing of 70,000 people for a fucking paper.
The paper
And speaking of the paper, let’s talk about what fascinating and vital research that overrides the pillar of informed consent this data was used for.
Oh: it wasn’t.
This data release wasn’t as part of a wider work - more the other way around. It was a self-contained data release of the type beloved by the open data movement (and me!): making information available so other researchers could pick it up and answer interesting questions. The paper attached to it is just to explore the data briefly and explain what it is.
On its own, this isn’t a problem. It’s a pretty nice thing to do. But when the data is this toxic, you should be able to point to an actual research justification for why this is a valuable way to spend your time, and why the questions it can answer justifies your grossly improper behaviour.
And that’s when things go from “terribly poor judgment” to “actively creepy”. Some research questions were used, as a way of demonstrating what the data can be used for, and Kirkegaard’s choices definitely say…something, about him.
His first research question was: what if gay men are basically just women? We have data on gender and we have data on sexuality; let’s see if LGB people provide different answers from straight people for their given gender! Let’s see if they’re basically the opposite gender!
You’ll be amazed to know he didn’t end up incorporating this into the paper, presumably because the answer was “of course not, you bigot”. But he did find time to evaluate whether religious people are just plain ol’ idiots - the methodology for which is checking the user’s response to various questions akin to IQ test entries. You know, the racist classist sexist thing.
As an aside, this kind of creepy superpositional homophobia is actually an improvement on much of the work I’ve found from Kirkegaard while digging into this, which is not superpositional at all: previous credits include such pseudoscience as arguing that letting low-IQ immigrants in will damage Danish society, and they should be subjected to brain implants and genetic engineering for entry, and (I wish this was a joke) checking whether immigrants commit more crime if they have tiny penises.
Neither of these questions are things that would pass actual institutional review as justifications for gathering data of this depth without informed consent. Neither of these questions are particularly original - there’s literature on both, using information gathered by qualified people in responsible situations. And no vaguely competent peer reviewer would look at this methodology, this dataset, and this set of conclusions, and determine that it constituted a publication.
The process
At this point any of you who are still reading and haven’t given up due to length, horror or disagreement might be going: how the heck did this ever get published? Even if the institution didn’t catch it - because it was recreational, because it was outside the department’s scope, whatever - the journal should’ve, right? There’s no way any reputable psychology journal would have let this slide without asking some hard questions.
Well, that’s where we descend yet further into academic ineptitude: you see, Kirkegaard submitted it to an open access journal called Open Differential Psychology, which is very very highly reputed. Mostly that’s thanks to their work of their editor, a Mr…oh.
Yep, Kirkegaard is publishing in a journal he’s the editor of, which isn’t actually new for him - the thing looks pretty much like a vanity press. In fact, of the last 26 papers it “published”, he authored or co-authored 13. When 50% of your papers are by the editor, you’re not an actual journal, you’re a blog.
Moreover, there wasn’t actually any review. There’s review for the paper, sure, but the underlying dataset? Pfft. Just throw that out, whatever. Which is pretty infuriating given that ODP reviews are handled by forum thread (open means open!) and the very first comment on the paper itself is that it is highly deficient in its approach to ethical questions around the collection of this data.
So no wonder this got out so easily, beyond the author’s own callous irresponsibility; the task of checking it fell to nobody. Those checks that were done happened after the release, not before.
The response
Unsurprisingly, when Kirkegaard publicised that he’d done this, a lot of people took issue, including myself, Kelly Hills and Ethan Jewett. Kirkegaard’s replies to questions opened with smug, self-assured ‘pfft, I did nothing wrong’:
{<1>}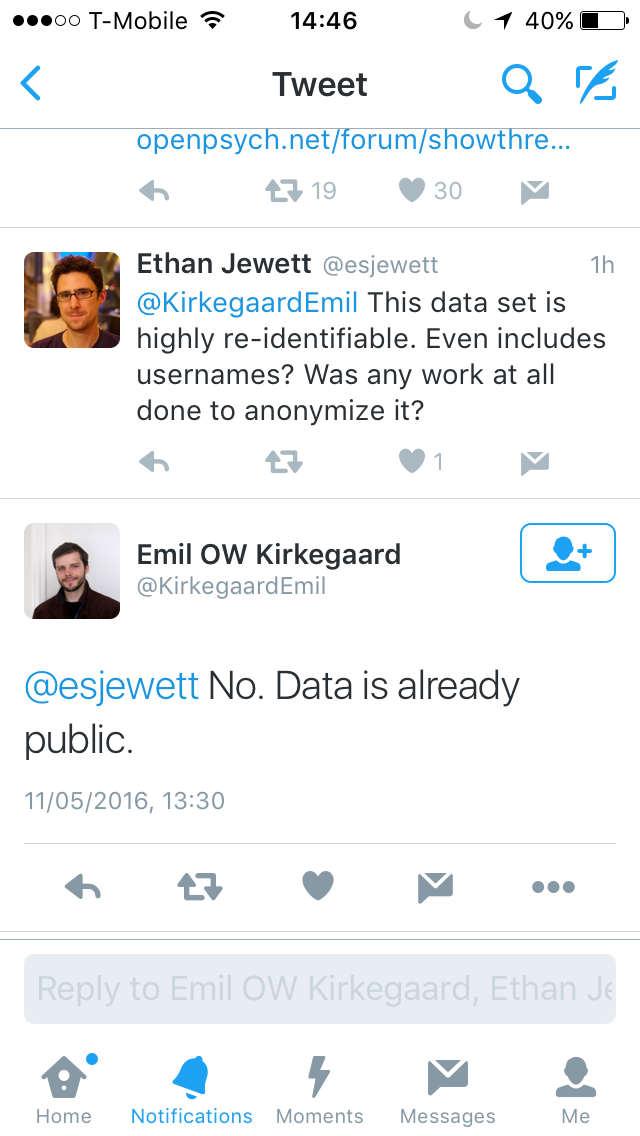 {<2>}
{<2>}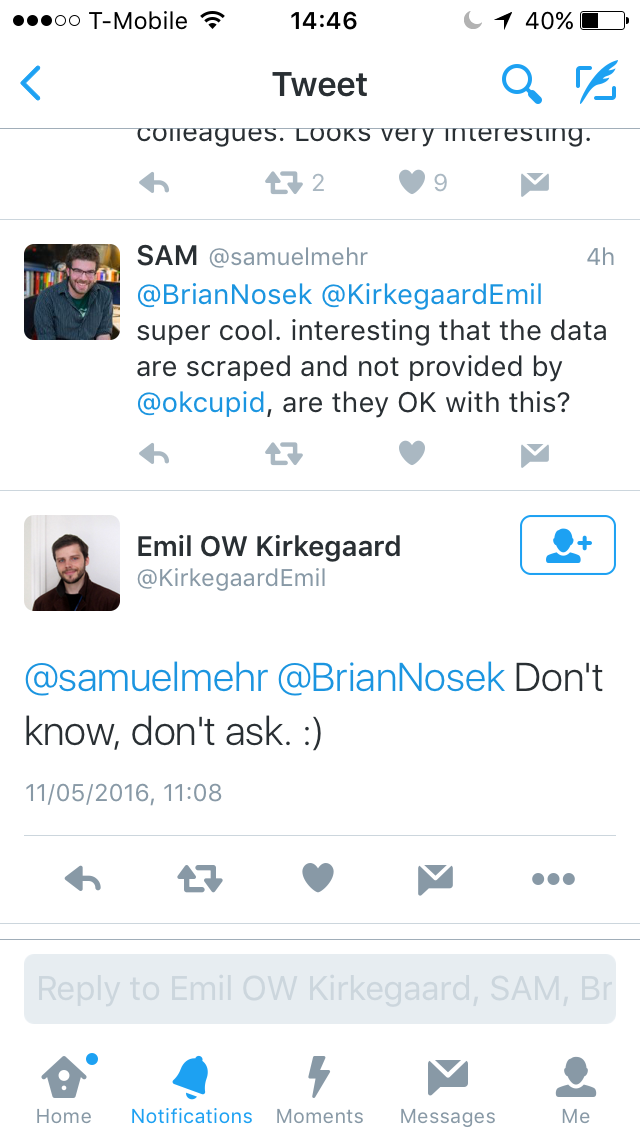
That’s just on specific, answerable questions; I didn’t do any work to anonymise stuff, it’s already public, who cares! Check with OKC? Eh, if I don’t ask they can’t say no.
When things get more abstract and philosophical, responses get worse. Kirkegaard first says that he’ll not discuss ethics at all - to be fair, given the irresponsibility of his actions thus far the motivation may just have been “not digging any further” if he has a lick of sense, but I doubt it - and then that he will, but only when “the [Social Justice Warrior] storm” goes away.
{kind=link}
![the [Social Justice Warrior] storm” goes away](https://ironholds.org/images/okc_twitter_4.jpg){kind=link}
This is not how academia works, at least not in the field Kirkegaard is publishing this data in and about: responsiveness to questions about the merits or implications of your work is as essential to good research as consent, as picking appropriate methods, as peer review. Refusal to discuss is not professional - and neither is throwing derogatory collective nouns at the people taking issue.
But there’s no indication here that Kirkegaard cares about professionalism; a very, very generous read is that he’s out of his depth in a space and field he doesn’t understand, was never trained in how to do this right, and panicking. A less generous read is that he’s privileged, willfully obtuse and deeply, deeply arrogant about where he has expertise and the work he does. Either way, this work is an embarrassing and unprofessional offering from an institute-affiliated researcher that puts vulnerable populations at risk.
The wider questions
While Kirkegaard himself engenders precisely zero sympathy - see the pseudoscientific racism above - there are wider questions here, for both academia and the open data community.
Academia needs to confront the fact that what happens outside the house follows you home. Kirkegaard is clearly out of his depth on everything he’s doing here, and just as clearly, he hasn’t been called on it. A lot of institutions and researchers I know insist that researchers restrict their work to areas where they can do a good job if they want support or university affiliation; they also insist those works go through the same ethical vetting that an in-school paper would, whether they’re a hobby work or not.
It’s safe to say that when you’re in the linguistics department and one of your advisees spends his spare time arguing for racially-biased gene therapy while doxing marginalised people, you’ve fucked this bit up quite severely.
At the same time, though, this is not a situation where we can point to institutional standards and individual impropriety, fix them and call it done. Unprofessional behaviour of this scale and with this number of layers is rare. Messing up the ethical implications of your work is common; it happens with grad students all the time. Ethical training in grad school is quite clearly not fit for purpose.
This isn’t to say it doesn’t cover valuable bits; this is just to that what it covers is nowhere near the breadth of modern data or modern scenarios. Ethical training tends to be oriented around two core sets of examples and illustrations - biomedical shitshows like Tuskegee or Milgram, and traditional survey design and data. These are good things to cover, but they don’t touch on the impact higher computing power has had on the ease of deanonymisation. They don’t include the ambiguity of data’s status and publicity on the internet, and the increased nuance it adds to the question of whether using something is Right or Wrong.
I’m not arguing lecturers shouldn’t be teaching Tuskegee or Milgram. I’m just saying they should teach AOL as well.
The open data problem is a lot simpler; we need to stop treating openness as an inherently good thing. Don’t get me wrong, I consider closed publishers to be festering sores on the body academic, but open data carries with it a risk to study participants. In the same way that papers go through a peer review process, datasets should also be evaluated and hammered and considered before they’re released, and sent back for more anonymisation if they’re not kosher. The rise of convenient code and data platforms has been amazing, and helped us be more transparent about our methods - but it’s also pushed the responsibility of ensuring that releasing the data does not pose harm back on to the researcher.
As this incident shows a dozen times over, that’s not something we can rely on.